
ML experiment tracking with DagsHub, MLFlow, and DVC
Learn how to track machine learning experiments using DagsHub, ML flow, and DVC.

This blog is part two of a two-part series introducing experiment tracking in machine learning (ML). Here, we cover the practical implementation of experiment tracking using a platform-based tool. Here's part one covering an introduction on how to track and analyze experiments in Machine Learning.
In practice, having some infrastructural setup, which can be referred to as a “workbench,” within the development pipeline is the way to go. It structures the workflow, but this is easier said than done. Although some cloud platforms have provided various out-of-the-box workbench platforms/services (like Vertex AI, Sagemaker, AzureML) ready for use, it doesn’t always cover all the use cases.
This often requires engineers to design and build an architecture for the workbench that best suits their workflow with external and in-house tools—which is outside the scope of this article. However, a typical workflow for this development stage will demonstrate how a specific problem might affect the workflow design and how the solution would play out with an out-of-the-box workbench.
Here, we’ll implement the experimentation workflow using DagsHub, Google Colab, MLflow, and Data version control (DVC). We’ll focus on how to do this without diving deep into the technicalities of building or designing a workbench from scratch. Going that route might increase the complexity involved, especially if you are in the early stages of understanding ML workflows, just working on a small project, or trying to implement a proof of concept.
Prerequisites
The following are required to follow along with this article comfortably:
- A basic understanding of ML
- A DagsHub account
You will need to connect your GitHub repository to DagsHub. This blog will show you how. This makes it possible to seamlessly version control your workflows with both GitHub and DagsHub, giving you the extra capabilities DagsHub provides and are necessary for ML workflows.
You can find the code for this project in this repository.
In this article, you will:
- Use DagYard to set up remote environments on Google Colab
- Version data with DVC and store it in DagsHub storage
- Train and track model experiments with MLflow on Google Colab
- Understand how use cases drive the ML development process
Case study: Train a model to translate alphabets to sign languages
As a young research student, you decide to work on a simple side project that classifies all the letters of the alphabet for sign language. You cannot train this model on your local machine because the computational cost of training is expensive (the kernel or runtime keeps crashing). You must figure out an easy way to train the computer vision model without incurring financial costs or worrying about infrastructure setup.
Unfortunately, the allocated grant won’t cover this project. So, you can’t afford to use cloud services (like virtual machines (VMs), workbench, etc.), and other experienced engineering colleagues that might be able to help brainstorm for this hiccup in setup (workbench) are too occupied with work.
Case study requirements
Have a remote workbench setup with better computing power to enable faster and easier training. You should also be able to track your experiments as you optimize for the best model and where different versions of the data will persist.
Note: There is a rich option of tools to pick from for every step in this article. The individual functionality and integration of these tools/platforms made implementing this use case easy.
The workflow architecture for the out-of-the-box workbench looks like this:
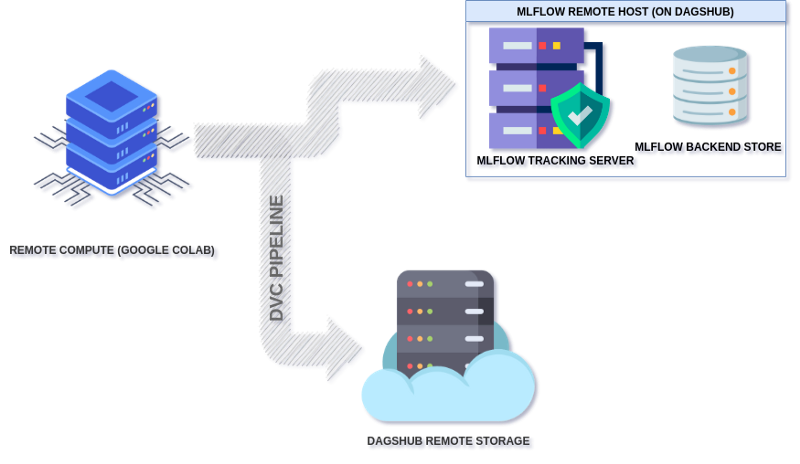
What is DagYard
DagYard is a configuration tool in the form of a notebook for DagsHub. It brings the DagsHub environment runtime of any “hosted” project to Google Colab by pulling all the components remotely and having them run on the Google Colab runtime while having direct access to all DagHub features.
This way, you don’t always have to worry about uploading or reloading data paths from Google Drive each time the kernel dies during training. You also won’t have to worry about the source code because you can now have everything in one place—plus you can now completely take advantage of Google Colab’s free computing power privileges.
You must have all the correct parameters and environment variables set at the beginning of the notebook. The authentication and configurations process is as straightforward as checking a few boxes from the list of available options and filling out the credentials—based on what you want to configure directly from DagsHub. VOILA!!! It’s all set for action.
DagYard is used to configure the environment for this demonstration.



After setting up the project. Run the “help function” and “black magic” blocks to pull the project from DagsHub into the Colab directory.

Version and store the data with DVC
About the Data
You will be working with image data. The file structure from the data source contains all the images and a CSV file with the image features for each image (i.e., annotation, labels, etc.). The image folder structure has train, test, and validation set splits.
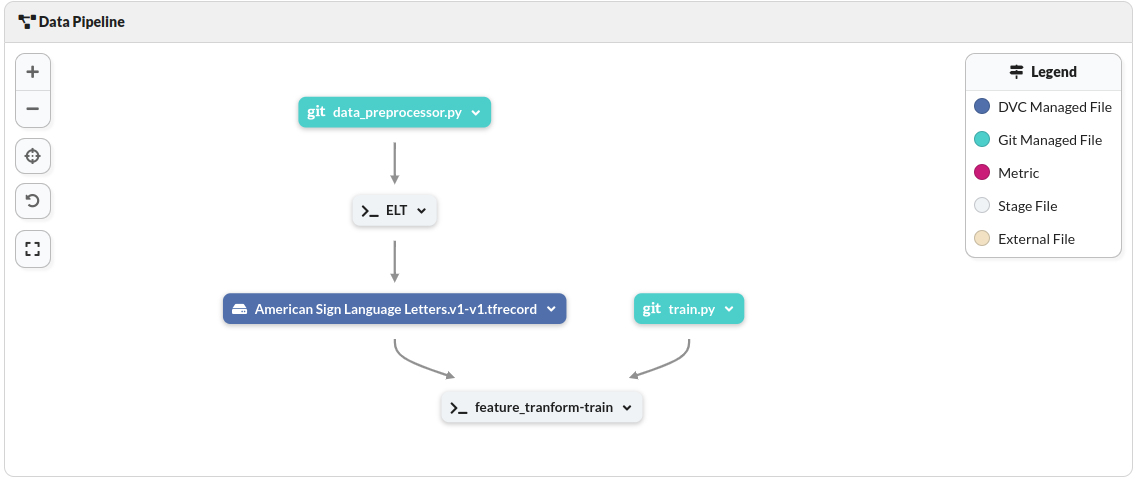
The data will be converted to a TFRecord format and recorded as a new data version. This preprocessing step reduces the data size and will make the training process easier since you are using TensorFlow. The src/data_preprocessing.py script performs this makeover.
Understand that you are working with the idea that data that comes from the data source can change at any time — which is what happens in practice. That is why you have chosen to version the data after preprocessing. Ideally, this represents the extraxt transform load (ETL) process.
DVC tracks data and uses a remote storage location to store the data. It supports a variety of remote storage locations like (s3 bucket, Google Drive, Azure blob storage, Google storage buckets, etc.). Although these are all excellent options, they might require a lot of configuration to set up or cost more because they are better suited for more complex workflows or robust solutions with scalability. If you’re thinking “Google Drive is free and easy to configure,” you are correct, but it limits your abilities when tracking training. You will get to understand this better in a bit.
Fortunately, DagsHub provides free remote storage with 10GB of space by default for every project (repository) that DVC supports.
Thanks to DagYard, it has already been configured as the remote storage location — but the data_store/data directory will serve as your feature store for the processed data.
Using MLflow for model experiments
As established earlier, it’s not uncommon to run many experiments in ML. It is essential to log all information from each set of experiments. The roadmap to arriving at a particular model becomes easier to trace.
You will make use of MLflow to manage the training information. Usually, it would require initializing and configuring a server to run on your local or remote machine. Its integration with DagHub allows us to use it just as you would when working on a proxied server. Select the MLflow option from the notebook configuration cell on the Dagyard to configure access to the MLflow tracking server (URI). This way, the tracking server is automatically running on DagsHub’s backend server.
Although this setup might not give complete control over MLFlow because you don’t have direct access to the management/running of the server or backend store (database), you can always use the MLflow client API to communicate with the tracking server. These are the kind of trade-offs that you might come across when building your solution with different tools.
Run experiment workflow
Since you have the project runtime on Colab, you can efficiently run the training with the paths to the source code and data. The train.py script has all you need to set, train, and log all the information required from an experiment.
The teeny-tiny issue is that on the free Google Colab plan, there isn’t access to a terminal console. Not to worry: you can use the good old hack of accessing the terminal from your notebook to run your experiments. You will also push and commit your change within a configured notebook (DagYard).
With the help of a pipeline, processes/workflows like this can be streamlined, seamless, and repeatable. A DVC pipeline executes the entire workflow—from data ingestion and preprocessing to model training.
https://gist.github.com/Tob-iee/7b950a34de5d55a36db972cb91c8d984
Disclaimer: Ideally, this is not good practice, but it gets the job done and demonstrates the workflow concept, in this case. Running Notebooks/run_experiment_workflows.ipynb will spin up the entire pipeline process.

You can also find two other notebooks (local_runtime.ipynb and colab_runtime.ipynb) in the Notebooks directory for local runtime training and Google Colab runtime training, respectively. Just for context, and if you would like to understand the above approach better, feel free to run them.
After the training process is complete, push the changes. Go back to the DagsHub interface, and you can see the workflow dags from the pipeline.
All MLflow experiments can then be seen and used from the MLflow UI.


Conclusion
Congratulations on making it this far! You have successfully learned the concept of experiment tracking and the thought process behind building and designing workflows to best suit your problem or use case.
In practice, the approaches to providing ML solutions are often unique across businesses. This equips you or your teammates to implement this MLOps workflow better and offer more value.
Resources
- The ASL dataset used for the project* Roboflow