
These 4 data platforms will transform how you handle data!
Transform your data management with these innovative data platforms for alternative data, semantic layers, cloud warehouses, and automation.

"Data is the new oil."
In 2006, British mathematician and data scientist Clive Humby popularized the phrase. Like oil, Clive suggested that data would drive the economy in the coming decades — and he was right!
As oil must be refined into gasoline, plastics, or chemicals to fuel our modern world, data must be processed, analyzed, and connected to unlock its true value.
Through this transformation, data becomes a powerful asset capable of driving intelligent software, enabling proactive customer experiences, and uncovering new revenue streams.
With the explosion of data from the Internet of Things, machine-generated sources, and everyday human activities, we are awash in this new digital oil. But how do we effectively harness its power?
This article discusses important data infrastructure and management technologies, including alternative data sources, universal semantic layers, cloud data warehouses, and data pipeline automation.
It spotlights innovative data platforms for data engineers and app developers seeking to transform their data handling and turn raw information into actionable insights.
Table of Content
- The rise of alternative data sources
- Introducing Exabel - the next-gen data platform
- Why do you need a Universal Semantic Layer (USL)?
- Using Cube to build trust with a semantic layer
- Cloud data warehouses, lakes, and data pipelines
- Build cloud data warehouses and lakes and manage data pipelines with ETLeap
- Building data pipelines without technical expertise with Aditum Data
The rise of alternative data sources
In recent years, the importance of alternative data has surged dramatically, becoming an indispensable tool for modern data-driven decision-making. This trend is driven by the increasing recognition that traditional data sources, such as financial statements and market reports, often fail to capture the complete picture of market dynamics and consumer behavior. Consequently, organizations are turning to alternative data to gain a competitive edge.

According to the AIMA report and Bank of America survey, approximately half of all investment firms currently use alternative data, and this number is expected to grow as more firms invest in new technology.
Alternative data comprises a wide variety of non-traditional data sources. For instance:
- Credit card transaction data offers insights into consumer spending patterns, while mobile device data can reveal location-based trends and behaviors.
- IoT sensor data provides real-time information from connected devices, and satellite imagery can monitor agricultural yields, environmental changes, or even traffic patterns.
Alternative data is significant because it can offer fresh perspectives and actionable insights that were previously unattainable. For example, hedge funds use social media sentiment analysis to gauge public opinion and predict market movements. Retailers analyze product reviews and web traffic to optimize inventory and marketing strategies.
As technology advances, the volume and variety of available data will grow, making alternative data increasingly critical for data-driven strategies. Embracing these unconventional data sources allows organizations to uncover hidden patterns, make more informed decisions, and achieve a competitive advantage.
Introducing Exabel - the next-gen data platform
As the demand for alternative data grows, Exabel emerges as a leading next-generation data platform catering to the evolving needs of modern investors. Founded in 2016 by Øyvind Grotmol, Exabel integrates over 50 pre-mapped datasets with fundamental KPIs from Factset and Visible Alpha, enabling real-time comparability and deep insights.
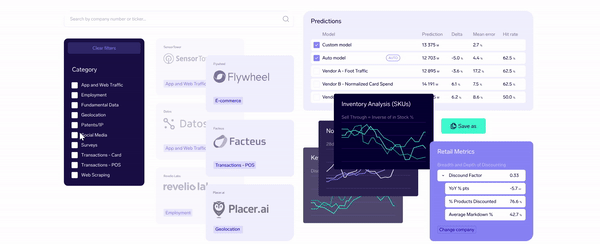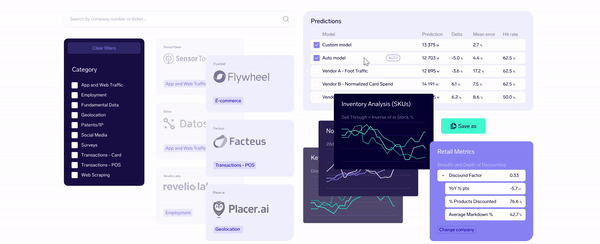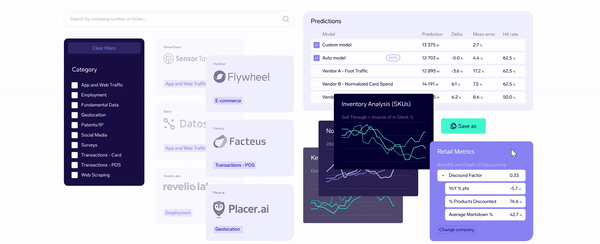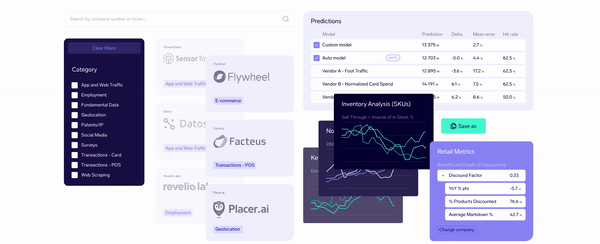
This data platform empowers investors with advanced analytical tools, including machine learning and AI, to uncover actionable insights beyond traditional backtesting methods. For investors, Exabel offers sophisticated prediction modeling of company KPIs through seamless workflows that combine fundamental, proprietary, and alternative data sources.
Additionally, Exabel supports data vendors by expanding their market reach and transforming their datasets into valuable insights for investors. In this data platform, the types of alternative data available can be categorized as follows:

With partnerships in eCommerce intelligence, labor market data, gig mobility, medical product procurement, and more, Exabel provides a robust ecosystem for discovering and effectively using alternative data.
Why do you need a Universal Semantic Layer (USL)?
A Universal Semantic Layer (USL) acts as a translation layer between raw data and meaningful insights, ensuring that technical and non-technical stakeholders can easily access and understand the data. This unified approach helps eliminate discrepancies between different teams using various tools and methodologies, often leading to data mistrust.
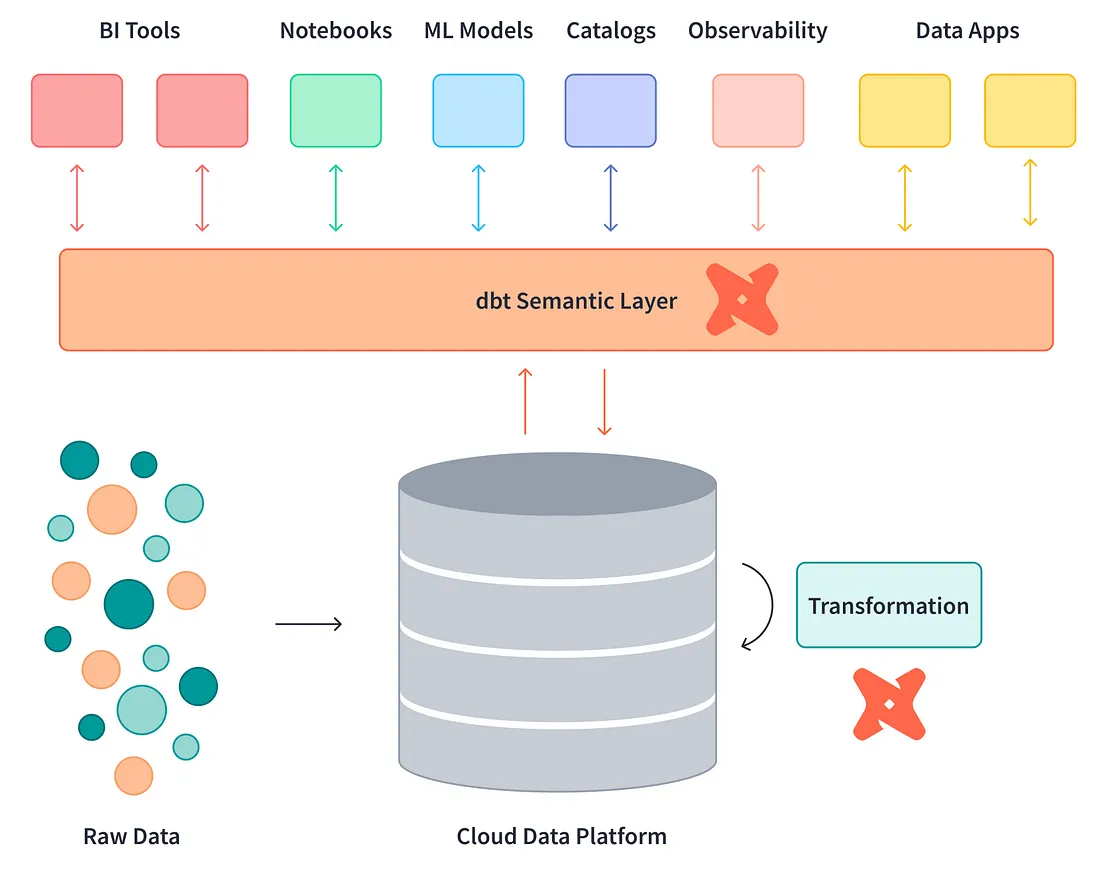
Image courtesy https://medium.com/@seckindinc/semantic-layer-future-of-self-serve-analytics-bdd22381de9e
At its core, a USL serves as the definitive source of truth for an organization's metrics. It standardizes metric definitions, ensuring consistency across the board. For instance, a retailer can use a USL to integrate sales data from multiple sources, such as in-store transactions and e-commerce sales, providing a comprehensive view of overall performance. By incorporating the context around how each metric was calculated, a USL helps prevent misinterpretations and erroneous decisions.
Using Cube to build trust with a semantic layer
Cube is a powerful data platform for implementing a Universal Semantic Layer, essential for unifying and standardizing data across an organization.
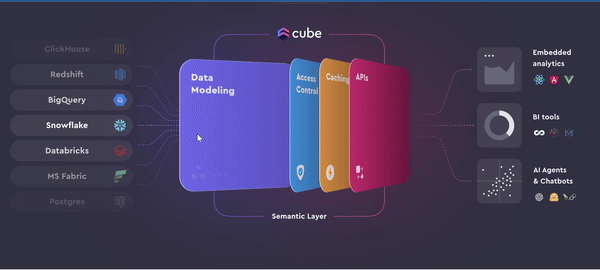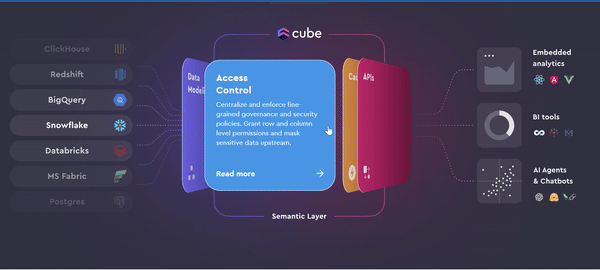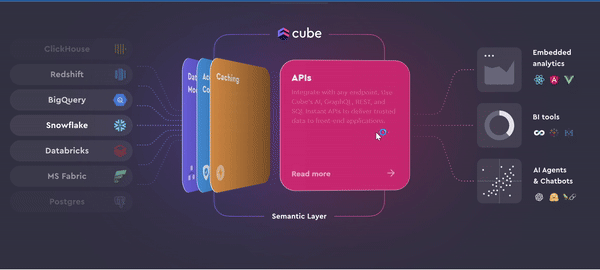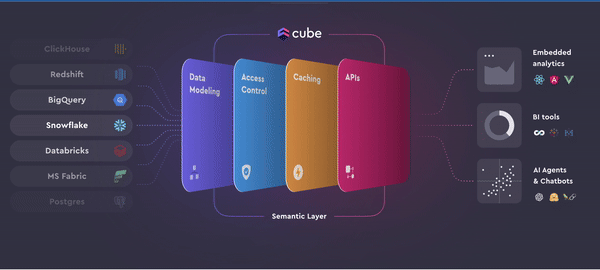
Data modeling: Cube centralizes your data models, ensuring consistent metrics across all applications. For instance, business metrics such as customer lifetime value can be defined once and used uniformly across internal dashboards and embedded analytics applications.
Data access and control: Cube enforces fine-grained access controls, granting specific permissions to users, teams, or applications. This ensures data security and compliance, allowing only authorized personnel to access sensitive information.
Caching and data performance: Cube’s two-level caching system uses in-memory cache and pre-aggregations to provide fast, cost-effective access to data. This minimizes latency and reduces the load on your primary databases, ensuring efficient data processing and quick query responses.
APIs: Cube’s REST, GraphQL, and SQL APIs smoothly integrate with your data stack, enabling real-time analytics and consistent insights across various tools. This flexibility ensures that your data remains accessible and performant, regardless of the application.
Using Cube, organizations can establish a reliable and efficient USL, enabling better data-driven decision-making and operational efficiency.
Cloud data warehouses, lakes, and data pipelines
Cloud data warehouses, lakes, and pipelines are transforming how businesses handle and analyze massive data.
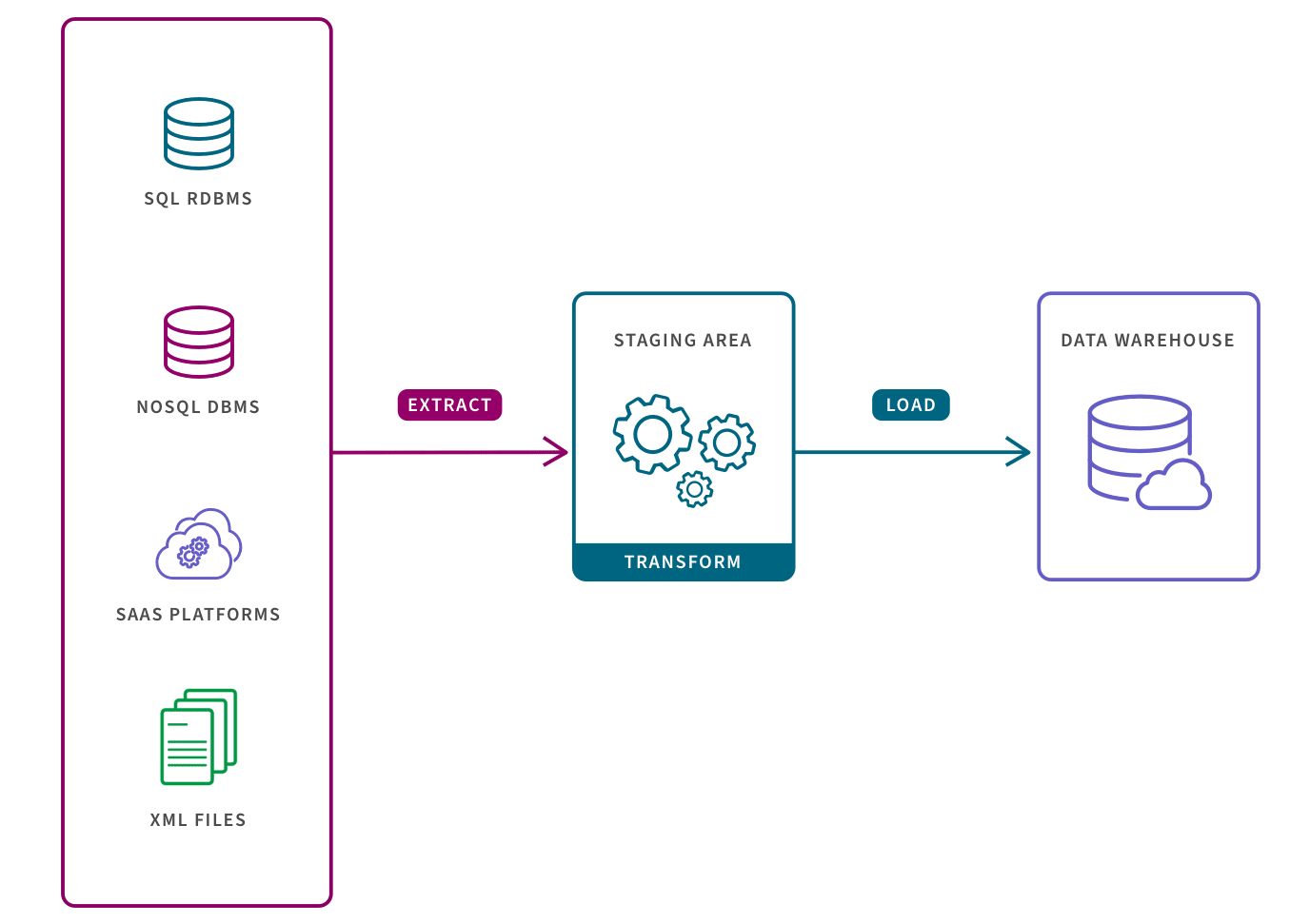
Image courtesy https://www.qlik.com/us/data-integration/data-pipeline
Data Pipelines are fundamental for moving data between systems. They involve steps to transfer, process, and standardize data. For example, a pipeline might move business expense records from an on-premises system to a cloud-based data lake, undergoing various processing stages before reaching a data warehouse for analysis.
A data lake is a vast repository that stores raw data in its original format. It accommodates all data types from various sources, whether structured, semi-structured, or unstructured. This flexibility allows organizations to store and manage extensive datasets without worrying about format or file type limitations.
In contrast, data warehouses store large amounts of structured data processed and organized for specific analytical purposes. They collect data from multiple sources, providing structured insights like product, customer, or employee information. The structured nature of data warehouses makes them ideal for performing fixed queries and analysis, enabling businesses to derive actionable insights and guide decision-making.
Leveraging cloud data warehouses, lakes, and pipelines can help businesses manage and analyze their data efficiently, leading to more informed decisions and enhanced operational efficiency.
Build cloud data warehouses and lakes and manage data pipelines with ETLeap
ETLeap simplifies the creation and management of cloud data warehouses, lakes, and data pipelines, offering a solid ETL solution for modern data teams. The data platform minimizes engineering effort by providing a no-code, analyst-friendly solution.
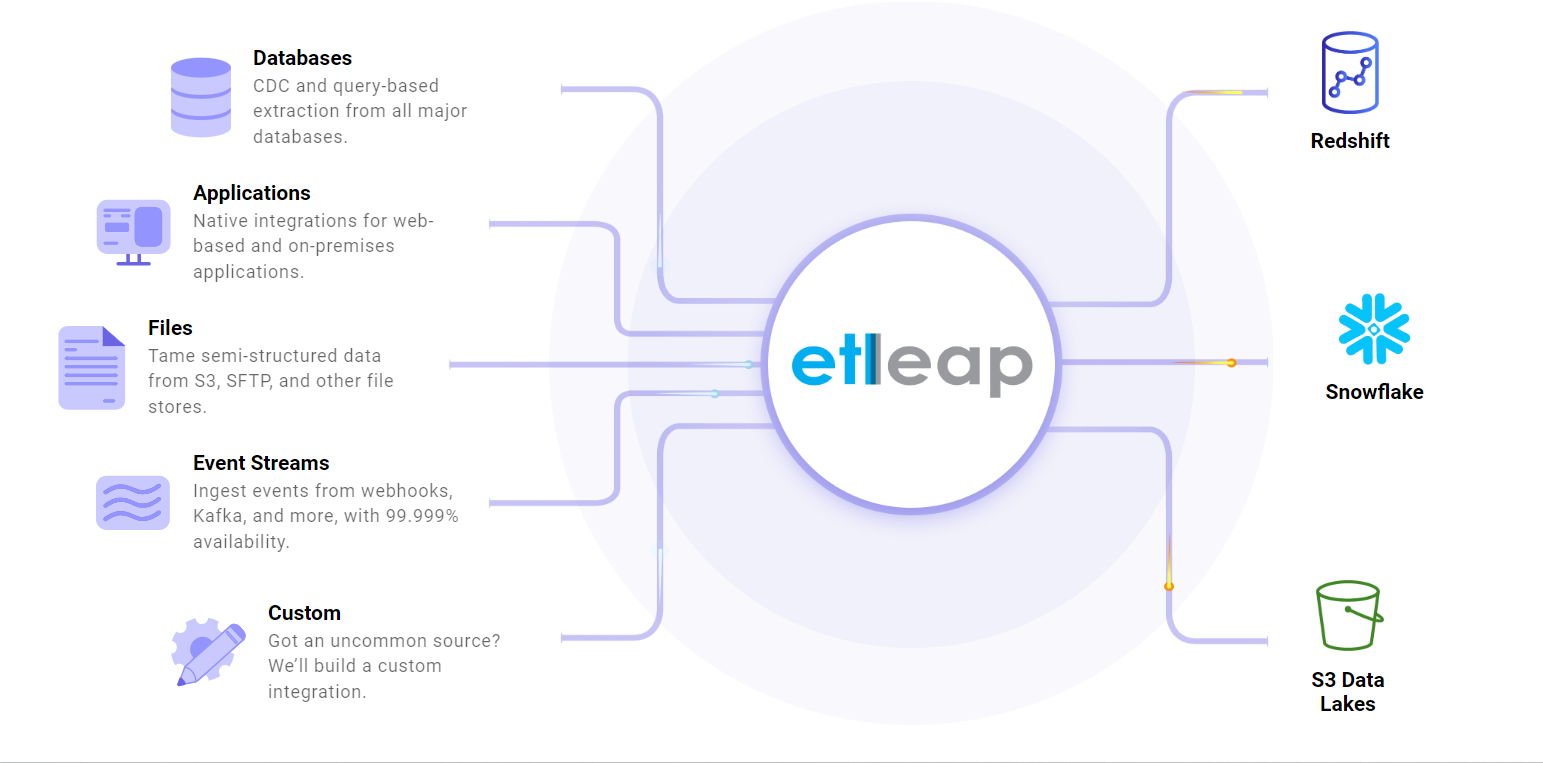
ETLeap empowers users to create flawless data pipelines from various sources to destinations like Amazon Redshift, Snowflake, or Amazon S3. With its intuitive Data Wrangler interface, data ingestion and transformation become streamlined processes, reducing time-to-value from months to hours.
ETLeap enhances data lakes by structuring raw data into analytics-ready formats using technologies like Apache Iceberg and Parquet (an open-source, column-oriented data file format designed for efficient data storage and retrieval). This approach accelerates query performance and ensures data integrity across AWS S3 and other cloud environments.
ETLeap leverages deep integrations with AWS services to optimize data warehouse operations on platforms like Redshift and Snowflake. It supports comprehensive data transformations and model creations, empowering modern data teams to derive actionable insights swiftly.
ETLeap allows data teams to harness the full potential of their data assets, enabling faster insights and informed decision-making across the organization.
Building data pipelines without technical expertise with Aditum Data
Aditum Data simplifies the creation and management of data pipelines with its intuitive, no-code platform, much like ETLeap. Designed to accelerate digital transformation, Aditum enables organizations to connect assets and transfer data within minutes, significantly reducing setup times that typically span weeks.

For instance, Aditum Data integrates with various enterprise tools, such as Salesforce, Google Analytics, and Amazon S3, allowing users to orchestrate data flows between these systems. Aditum’s user-friendly interface allows for fluid development, monitoring, and maintenance of industrial data pipelines. It ensures sturdy security and compliance with stringent data protection requirements, operating entirely within existing IT infrastructures and under your control.
With built-in monitoring, alerting, and customizable operational metrics, Aditum Data enhances operational efficiency while minimizing manual pipeline development and maintenance costs. Aditum offers scalable solutions for companies managing large data volumes, supporting agile data operations without the complexities of traditional coding-intensive approaches.
Wrapping Up
These innovative data platforms showcase the powerful impact of modern data handling. They harness alternative data sources, implement universal semantic layers, and leverage cloud data infrastructure, enabling organizations to unlock the true value of their data. With data growing from diverse sources like IoT and social media, mastery of these technologies will be crucial for intelligent decision-making and sustaining competitive advantage.
